David Gomes from Cursor recently shipped a pull request that deleted 15,000 lines of TypeScript and replaced it with 200 lines of plain prose. Same feature, mostly. Less code than this blog post.
The easy read is "markdown is the new code." It isn't. The interpreter changed. The swap only works for tasks that can verify themselves at inference time.
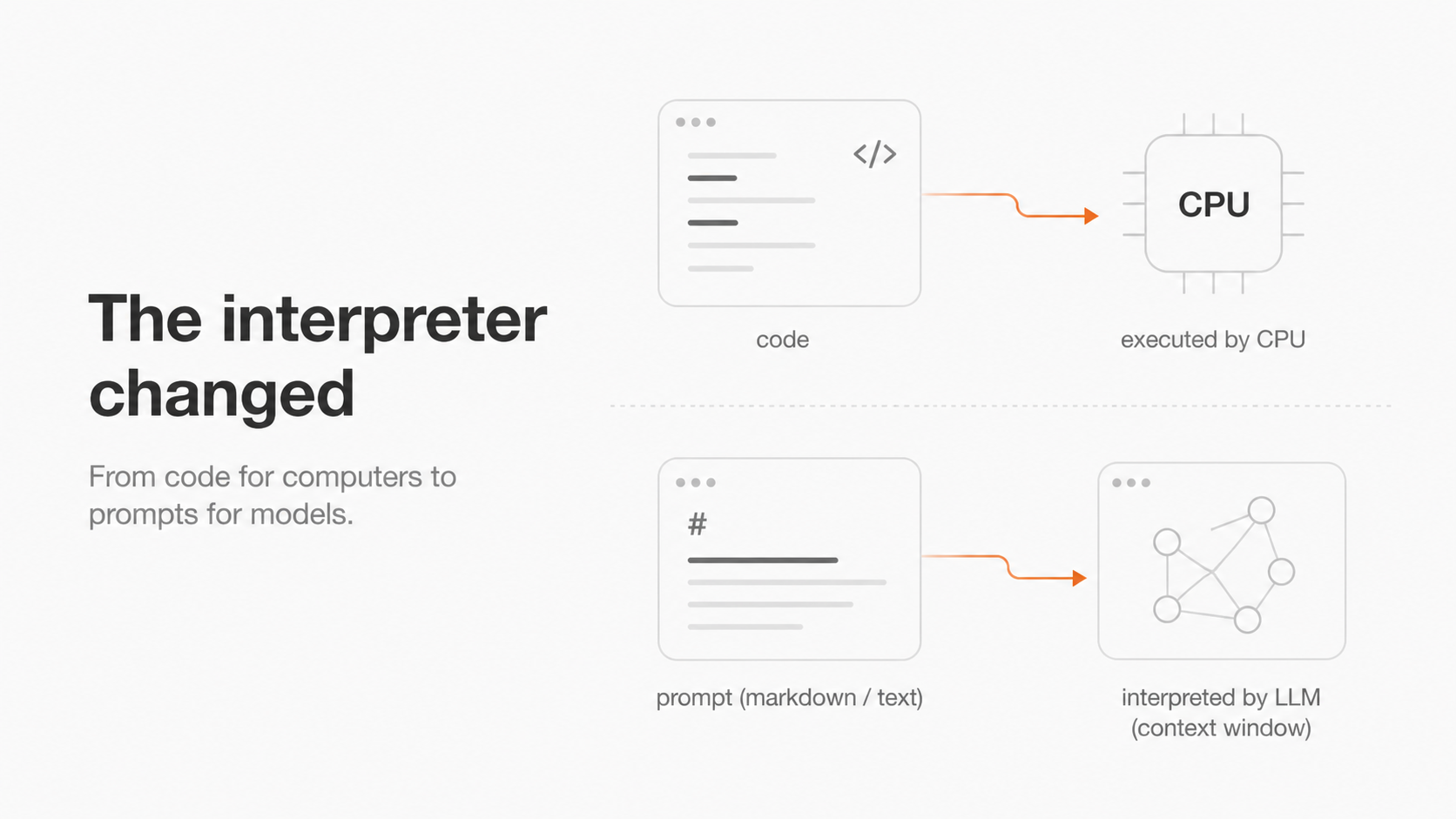
The interpreter changed#
The format barely matters. It could be YAML, plain text, or a custom DSL. An LLM is reading the file now, not a CPU.
Andrej Karpathy has been making a version of this point for a while. In Software 1.0 you write code and the CPU executes it. In Software 2.0 you write training data and architectures, and gradient descent produces weights. In Software 3.0 you write prompts. The LLM is the interpreter. The context window is your program.
I didn't fully get this framing until I watched the Cursor PR play out.
Cursor's worktree refactor is a clean instance of the 3.0 pattern landing in production. The 15k lines of TypeScript described how to create worktrees, isolate them, run setup scripts, and judge outputs. The 200 lines of prompt describe the same things. The difference is who reads them.
In his recent Sequoia talk, Karpathy described building a small app called MenuGen. You photograph a restaurant menu and it generates pictures of each dish. Then he realized you could hand the photo to Gemini with a one-line prompt and get the same output. "That app shouldn't exist," he said. The model swallowed the application layer.
Cursor's worktree feature got partially swallowed the same way. I keep finding layers like this in code I wrote two years ago.
Where the swap stops working#
If "prompts are the program" were the whole story, every codebase would be shrinking by 75x right now. They aren't. Cursor itself only deleted the worktree feature, not the entire application. There's a reason for that.
The major labs train these models with reinforcement learning in environments where outputs can be automatically verified. Math problems where you can check the answer. Code where you can run the tests. Tasks with a verification signal get practiced thousands of times during training. Tasks without one do not.
The result is jagged intelligence. The same model refactors a 100,000-line codebase, then tells you to walk to a car wash 50 meters away because the car wash is so close. Capability is high in the domains the labs optimized for and uneven outside them.
Replace code with a prompt only when the task can verify itself at inference time. Without that, you're trusting reliability the model was never trained to deliver.
The parts of Cursor's refactor that work cleanly: "create a worktree at this path," "run this setup script," "open a PR from the worktree." These are short, code-shaped, and verifiable in a single step. Either the worktree exists or it does not. Either the script ran or it errored. The model is operating well inside the region the labs optimized for.
The part that wobbles: "stay inside this worktree for the entire session and don't touch files outside it." Gomes is candid about this and calls the new approach "vibes-based." His exact phrasing was "knock on wood, please don't forget about this." There's no inference-time signal for whether the agent drifted outside its sandbox. It's a soft constraint stretched across hundreds of tool calls. Smaller models like Haiku deviate frequently. Composer and Grok hold the line better, but not perfectly.
The old TypeScript implementation enforced isolation at the system level. The agent literally couldn't write files outside its worktree because the code wouldn't let it. The new implementation asks the agent nicely.
One is a guarantee. The other is a probability distribution. That distinction matters more than the worktree story it came out of.
The decision every team is now making#
The build-vs-prompt question is the most important architectural decision most teams will make in the next year. It hinges on whether the task can check itself at inference time. If it can't, the demo will still look fine. The prompt is fresh, the session is short, the path is happy. Production sessions don't get any of those things.
"We shipped it as a prompt and now we're iterating on the prompt." I keep hearing some version of that sentence. Whether it describes a working product or one that's slowly breaking depends on something most of the speakers haven't checked.
What is missing#
Gomes hints at the missing piece near the end of his talk. Cursor is now writing evals to test whether agents stay inside their worktrees. Two simple scorers: did the agent do work in the right place, and did it avoid the wrong place. They use these to iterate on the prompts and to add training tasks for their in-house Composer model.
That's the bigger gap. When your guarantees move from deterministic to probabilistic, your testing discipline has to move with them. Unit tests, integration tests, and type systems all assume a deterministic interpreter. Prompts don't have that.
We need a testing discipline built for stochastic systems. Cursor's scorers are crude, but they're already doing what most teams shipping AI features aren't: measuring.
If we replace code with prose, we need a way to measure when the prose is quietly failing.