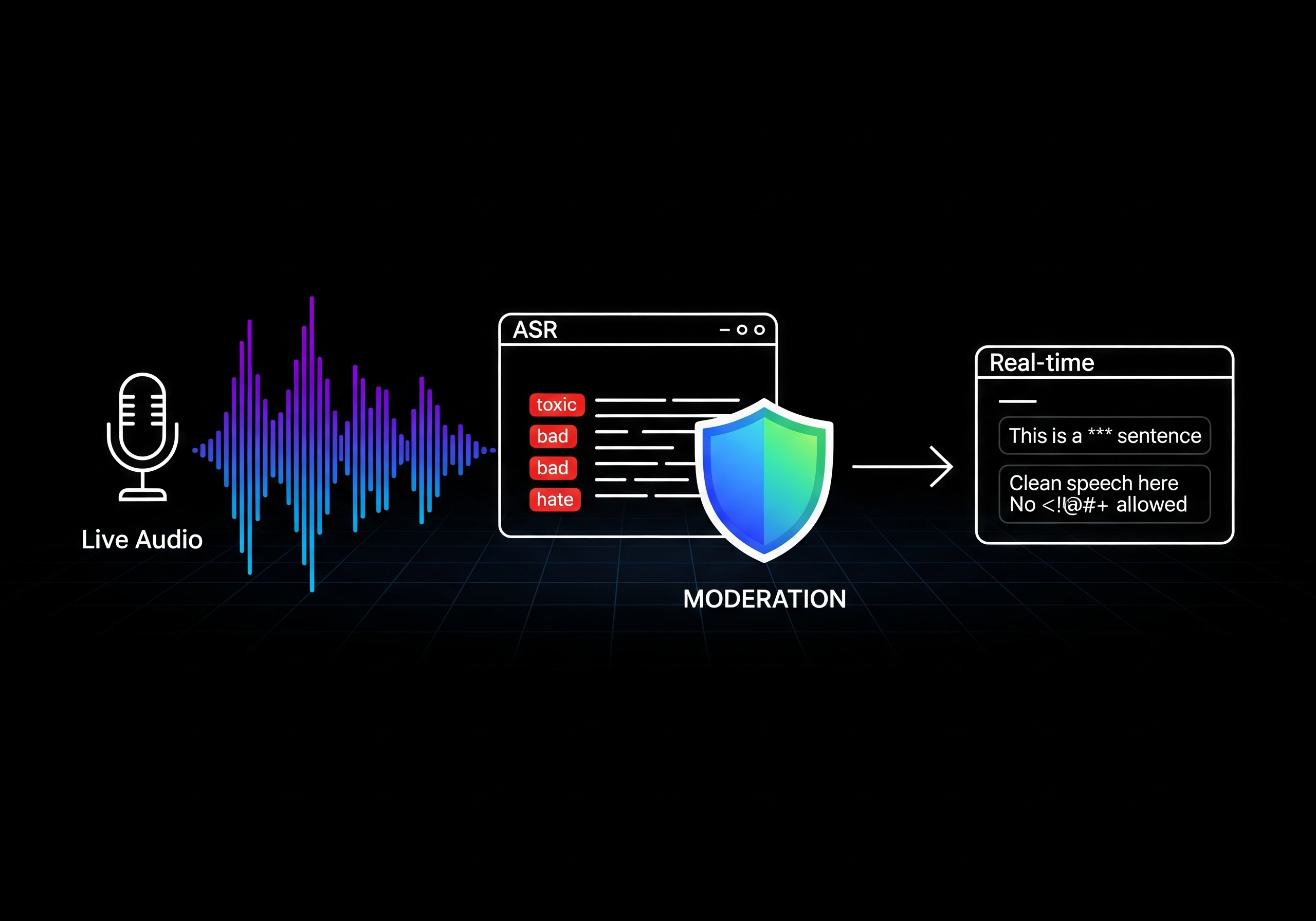
TL;DR#
I built a realtime “listen → transcribe → filter → show” pipeline. It skips silence, turns speech into text, checks if the text is toxic, and masks only the toxic words. There are two speech-to-text (ASR) engines: wav2vec2 (fast) and Whisper (more accurate). With wav2vec2, average end-to-end latency is under 400 ms. With Whisper, it’s ~1.1 to 1.8 s but the text is cleaner. The sentence-level toxicity model reached F1 0.807, Precision 0.835, Recall 0.781, PR-AUC 0.845.
This started as a Natural Language Programming (NLP) course project. Not a paper - just a practical build to learn the full workflow and measure latency.
Why I built this#
Live audio is everywhere: streams, games, voice chat, assistants. Most moderation happens after the fact. I wanted to see if we can catch harmful language as it happens without making the conversation feel slow. The goal: fast enough, accurate enough, and not annoying.
What’s inside#
-
Silence skipping (VAD). WebRTC VAD only lets speech frames through, so we don’t waste time on silent parts.
-
Two ASR choices.
- wav2vec2-base → lowest latency
- Whisper-base → higher accuracy (uses a small buffer)
-
Two-step toxicity check (DistilBERT).
- Sentence classifier decides if the line is toxic.
- If yes, a span tagger finds the exact toxic words to mask.
-
Smart masking. Only the toxic spans get masked. Everything else stays readable.
-
Parallel pipeline. Audio capture, ASR, and moderation run in parallel with small buffers to balance speed and context.
How it works (under the hood)#
Capture & gate: Mic audio at 16 kHz (mono) goes through WebRTC VAD. Only frames tagged as speech enter the queue.
Transcribe: A small buffer groups speech frames. For Whisper I use a ~2 s window with a 0.5 s step to keep context while staying responsive. Each chunk is sent to the chosen ASR backend and the ASR latency is recorded.
Moderate: The sentence classifier scores the transcript. If the probability crosses a threshold (default 0.70), the token‑level tagger predicts BIO spans for toxic words. I mask just those spans (or the whole sentence if token masking is disabled). The final output is the cleaned text and the total latency = ASR + moderation (+ optional span tagging).
Pseudocode snapshot#
# AudioCapture → queue
while running:
frame = mic.read()
if vad.is_speech(frame):
audio_q.enqueue(frame)
# SpeechToText → queue
buffer = []
while running:
frame = audio_q.dequeue()
buffer.append(frame)
if silence>THRESH or duration(buffer)>=BUFFER_MS:
audio = concat(buffer)
text, asr_ms = asr.transcribe(audio)
transcript_q.enqueue(text, asr_ms)
buffer.clear()
# ModerateText
while running:
text, asr_ms = transcript_q.dequeue()
p = sentence_clf(text)
if p>=THRESH:
spans = token_tagger(text)
clean = mask(text, spans)
else:
clean = text
total_ms = asr_ms + moderation_ms
out_q.enqueue(clean, total_ms)Datasets and models#
- ASR checks: LJSpeech for WER, CER, and latency
- Toxicity training: Jigsaw Toxic Comments (sentence level) and Toxic Spans (character-level tagging)
- Backbones: DistilBERT for moderation, wav2vec2 or Whisper for ASR
Training & eval setup (quick facts)#
- Fine‑tuning: DistilBERT (sentence classifier) for 3 epochs on Jigsaw; DistilBERT (token BIO head) for 3 epochs on Toxic Spans.
- Hardware for fine‑tuning: single T4 GPU.
- ASR eval: 100 random LJSpeech utterances.
- Toxicity eval: 2,000 Toxic Spans test sentences (token tagging) + held‑out Jigsaw split for sentence classification.
- Whisper streaming config: ~2 s buffer, 0.5 s hop (overlapping windows for context).
Results#
ASR quality and latency#
| ASR model | WER % | CER % | Typical E2E latency | RTF |
|---|---|---|---|---|
| Whisper-base | 6.7 | 1.9 | ~1.2 s | 0.31 |
| wav2vec2-base | 10.0 | 4.8 | ~139 ms | 0.02 |
Toxicity detection (sentence level)#
| Metric | Value |
|---|---|
| F1 | 0.807 |
| Precision | 0.835 |
| Recall | 0.781 |
| PR-AUC | 0.845 |
| Threshold | 0.70 |
Span tagging (word/char level)#
| Task | Metric | Value |
|---|---|---|
| Toxic spans | F1 | 0.623 |
End-to-end latency by mode#
| Path | Typical E2E | Best fit use case |
|---|---|---|
| wav2vec2 path | < 400 ms | Interactive chat and games |
| Whisper path | 1.1 to 1.8 s | Streams and broadcasts |
Design choices that helped#
-
VAD first to cut silence and reduce perceived lag
-
Short streaming buffer for Whisper to keep context without big delays
-
Two-stage moderation so the span tagger only runs when needed
-
Threshold tuning (default 0.7) to lower false positives
- Lower it → more recall (catches more, masks more)
- Raise it → more conservative (masks less)
-
Span masking beats whole-sentence redaction for readability
Evaluation details (what I measured)#
- ASR metrics: WER, CER, RTF, and measured per‑chunk latency.
- Moderation metrics: sentence‑level precision/recall/F1/PR‑AUC; token‑level span F1 (BIO tagged spans → character spans).
- Throughput & latency: total E2E time per utterance and component‑level costs (ASR dominates; token tagging is ~5 ms, sentence scoring is a few ms).
Error patterns (and what to do about them)#
- False positives: harmless idioms (like “break a leg”) and quoted slurs can be flagged. Using context checks or allow‑list rules for quoted content will help reduce False Positives.
- False negatives: implied/multi‑sentence abuse or contextual insults can slip through. Lowering the threshold or adding short memory across turns will help.
- ASR issues: the worst 5 to 10% of utterances (fast speech, rare words) hurt moderation the most. Considering to fallback or ask‑to‑repeat prompts on low ASR confidence chunks will help reduce the ASR issue.
Latency budget & runtime notes#
- wav2vec2 path: ~139 ms ASR on CPU‑friendly settings; total < 400 ms E2E is realistic for interactive use.
- Whisper path: ~1.2 s ASR due to larger context; total 1.1 to 1.8 s with span masking.
- Token tagger: ~5 ms per utterance; negligible.
- Bench box: Quad‑core CPU, 32 GB RAM, GTX 1050. Training/fine‑tuning done on a single T4.
Where this fits#
- Live streams & social audio: tiny delay + span masking to ease manual review
- In-game voice chat: low-latency path with a conservative threshold
- Assistants & contact centers: edge/on-device moderation to avoid server trips
Limitations#
- ASR errors can confuse the classifier (homophones are tricky)
- Context is hard: sarcasm, quotes, multi-turn abuse still cause misses
- Domain shift: typed comments ≠ spontaneous speech
- Audio bleeping needs a small delay; text masking is instant
What’s next#
- Hybrid ASR router Start with wav2vec2 for short/clear utterances. If ASR confidence is low or the utterance is longer, switch to Whisper. Keep chunked streaming to cut perceived delay.
- Short memory + diarization to handle ongoing abuse across turns
- Edge optimization: quantization/distillation to aim for < 250 ms E2E on laptops
- Reviewer UI: quick human review for tough calls, with continual learning
Conclusion#
I went in thinking model choice would decide everything. It didn’t. VAD, tiny buffers, and masking strategy mattered just as much. The result isn’t perfect, but it’s useful and it runs fast enough to feel natural.
Github Repo : https://github.com/hdprajwal/Guardscribe
Paper : https://github.com/hdprajwal/Guardscribe/blob/main/toxic_content_filtering_in_stt.pdf