Finishing a change and then naming the commit and branch always felt like the least interesting part of the workflow. Small tasks, but they happen often enough that the friction adds up.
The rule: the model can suggest, never act. Gitwise reads local git state, proposes a result, and waits for confirmation before it runs anything. That keeps the tool useful when the first answer is close but not right.
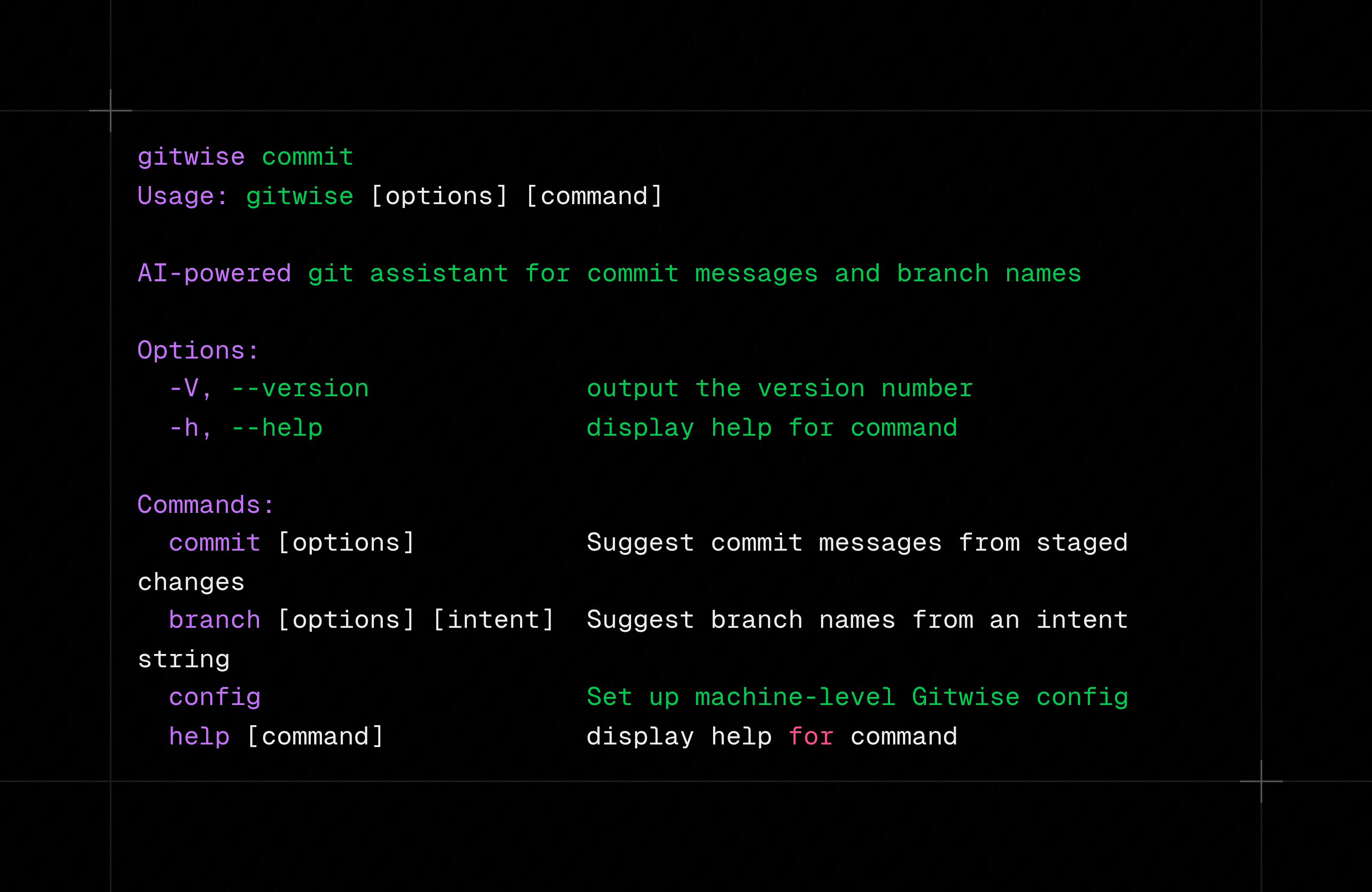
What it does#
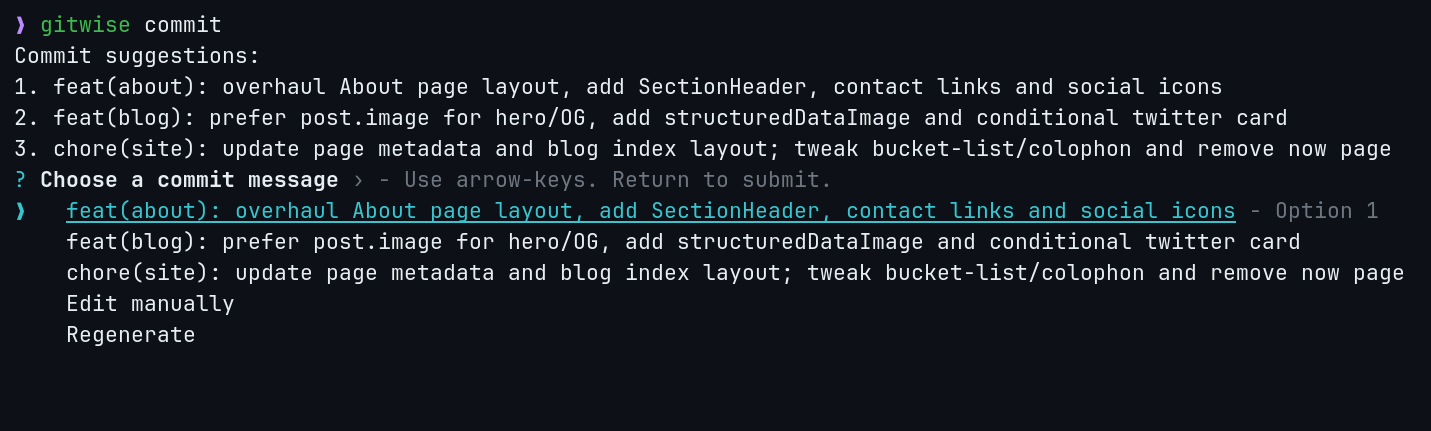
gitwise commit reads the staged diff, looks at recent history for style, and proposes a commit message that you can accept, edit, regenerate, or cancel. gitwise branch "add github oauth login" turns plain English into a branch like feature/add-github-oauth-login and creates it only after confirmation.
The goal was to remove repetitive naming work without adding cleanup work when the model misses the mark.
How it works#
For commit generation, Gitwise uses git diff --staged as the main input and recent commit history as lightweight context for style matching. The model response is validated against a schema before it is shown, so malformed output fails early instead of leaking into a git command.
Configuration is layered so the tool works both as a personal CLI and as a repo-specific helper:
~/.gitwise/config.json -> machine-wide defaults
.gitwise.json -> repo-level overrides
~/.gitwise/.env -> global secrets
.env -> repo-level secrets
Repo config overrides global config. Environment variables override both. That keeps the default setup simple while still making it easy to change models or endpoints per repository.
Safety model#
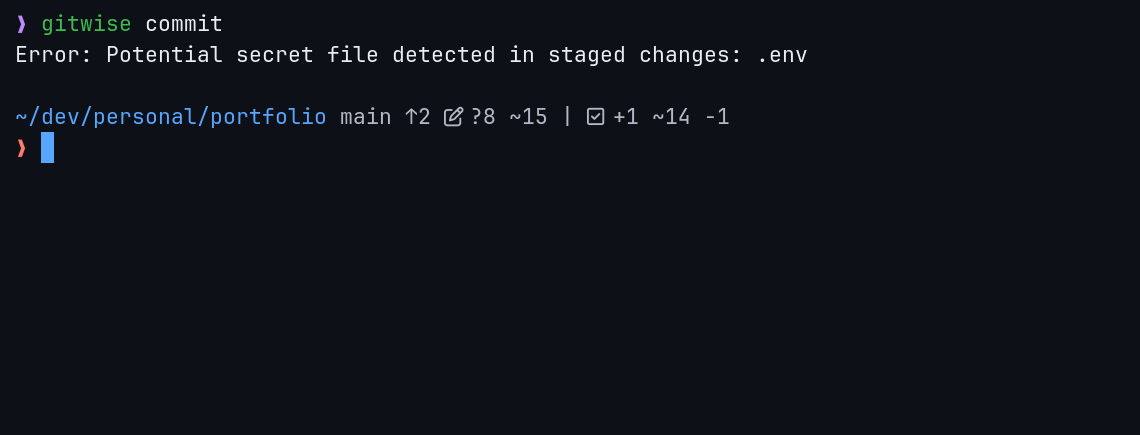
Before any diff leaves the machine, Gitwise runs a secret scan over the outbound prompt payload. If the staged changes look like they contain an API key, token, or password, the request is blocked and the CLI tells you which lines triggered the stop.
I added that after nearly sending a .env file to OpenAI during testing. The scanner is intentionally conservative. I would rather explain a false positive than a leaked key.
Decisions and tradeoffs#
I kept the tool interactive instead of making it one-shot because the first suggestion is often close but not perfect. Accept, edit, regenerate, and cancel is a better workflow than rerunning the whole command from scratch. I used Bun instead of Node because cold-start time matters for a CLI that sits in the middle of normal development, and faster startup keeps the tool out of the way.
I also validated model output against a schema instead of trusting it blindly. If the response is invalid, the command should fail before git ever sees it. The secret scan sits on the outbound path for the same reason: the risky boundary is the provider call, so the guard belongs before the request, not as a warning after it. Layered config followed from how teams actually use tools like this across projects with different models and endpoints; repo overrides let the tool adapt without turning setup into a chore.
What I would change next#
The current secret detector is regex-based. It catches obvious shapes like AKIA... and sk-..., but less obvious leaks still slip through. An entropy-based pass on top would cover more of the long tail.
The next obvious extension is PR description generation. The diff parsing, confirmation loop, and output validation already exist. It mostly needs a different prompt and schema.